



在机器学习的过程中,我们经常需要评估一个模型的性能,或者对比两个不同模型的优劣。能够正确地选择合适的评估标准,对一项机器学习任务的成败来说尤为重要。这不是一件容易的工作,因为它考验每个人对数据的熟悉程度,不同的数据我们会倾向于用不同的评价标准。在开始一项机器学习任务之前,我们都应该要问自己两个问题:
- 应该用什么指标来评价最后得到的模型的好坏?
- 当这个指标达到什么数值,我就已经完成这项任务了?
这两个问题不但可以让你对任务进度达到心中有数,并且有时还可以防止你在一项不可能的任务上浪费时间,因为可靠的可量化的指标并不存在。总而言之,这很重要。
常用的评价指标
不同类型的机器学习任务适用不同的指标,常见的任务大体上可以分成下面几大类
- 分类(Classification)
- 回归(Regression)
- 检测(Detection)
分类
分类是指对给定的数据项预测该数据所属的类别。一个简单的例子是垃圾邮件检测。输入邮件的文字内容和元数据(比如发件人、发送时间等),而输出则是一个标签,表明邮件是“垃圾”还是“正常”。分类任务常用的指标有:
- 混淆矩阵(Confusion Matrix)
- 分数(F1 Score)
- 准确率(Accuracy)
- 平均类准确率(Per-Class Accuracy)
- AUC(Area Under Curve)
- 对数损失(Logarithmic Loss)
混淆矩阵
混淆矩阵只能用于二分类问题当中(当然,多分类问题可以容易地转变成二分类问题)。在邮件分类的例子中,假设我们规定正常邮件为正样本(Positive),垃圾邮件为负样本(Negative),正负其实只是一个标签,在我们的邮件分类问题中并不重要。
现在假设我们有200封正常邮件,有100封垃圾邮件。同时,我们的分类器并不完美,它把150封正常邮件判断为Positive,把50封正常邮件判断为Negative,把10封垃圾邮件判断为Positive,把90封垃圾邮件判断为Negative。混淆矩阵(或叫混淆表) 是对分类的结果进行详细描述的一个表,对于我们上面的结果,混淆矩阵为
Confusion Matrix | 预测为正类的样本数 | 预测为负类的样本数 |
正样本 | 真的正类( True Positive):150 | 假的负类( False Negative):50 |
负样本 | 假的正类( False Positive):10 | 真的负类( True Negative):90 |
值得注意的是,在统计学中,假的正类(False Positive)也称为一类错误(
Type One Error),假的负类(False Negative)也称为二类错误(Type Two Error)。当然,在这种情况下,正负标签往往有着特定的含义,详细情况请见维基百科。言归正传,从混淆矩阵中可以延伸出一系列的二分类模型的评估指标,常见的有:
True Positive Rate(a.k.a.Recall,Sensitivity,Hit Rate)
True Negative Rate(a.k.a.Specificity,Selectivity)
False Negative Rate(a.k.a.Miss Rate)
False Positive Rate(a.k.a.Fall-out)
除此之外,还有常和 Recall 一起出现的
Precision,也叫Positive Predictive Value其中 FDR 全称为
False Discovery Rate 与 Positive Predictive Value 相对应的是
Negative Predictive Value其中 FOR 全称为
False Omission RateF1 Score
或者我们把 True Positive,False Positive 和 False Negative 代入其中
上面的式子至少有两点值得我们注意的:第一, 分数是一个0到1之间的数值,当分数越接近1时,模型性能越好;第二, 分数的计算过程中,Precision 和 Recall 是同等重要的(与不加权平均数类似),这种评估标准在一些情景中可能不太适用。比如癌症的诊断中,错诊(把良性肿瘤诊断为癌症)和误诊(把癌症诊断为良性肿瘤)的后果是完全不一样的。前者只是虚惊一场,可能在后续检查中就可以把诊断结果纠正。而后者可能会使病人错过最好的治疗时期,并付出生命的代价。
准确率
准确率的一个变形是平均类准确率,即计算每个类别下的准确率,然后计算它们的平均值。
比如上面的垃圾邮件例子中,平均类准确率为 。
通常情况下,如果每个类别下的样本数量不一样,则平均类准确率不等于准确率。这一点非常重要,因为当样本在类间分布不均匀时,数量较多的类别对准确率影响特别大。考虑下面的例子,假设我们的样本中有299封垃圾邮件,有1封正常邮件,那么我们的分类器只要无脑地把每一封邮件都判定为垃圾邮件就能达到较高的0.99的准确率,但这个分类器的平均类准确率只有0.498,连一半都不到。
当然,平均类准确率也有它的缺点。比如,如果一个类别的样本特别少,那么它的准确率的方差一般会比其他类别的准确率要大,也就是说它的准确率并不稳定,并且会在平均类准确率中把其他类别的准确率的可靠程度拉低。
AUC
有了
True Positive Rate,False Positive Rate等一系列指标,我们就可以选取不同的两个指标画曲线,并计算 AUC 了。这里 AUC 真的就是指曲线下的面积(area under curve)。比如常用的曲线有 ROC 曲线(a.k.a. AUROC),Precision-Recall 曲线等。下面是两个例子:
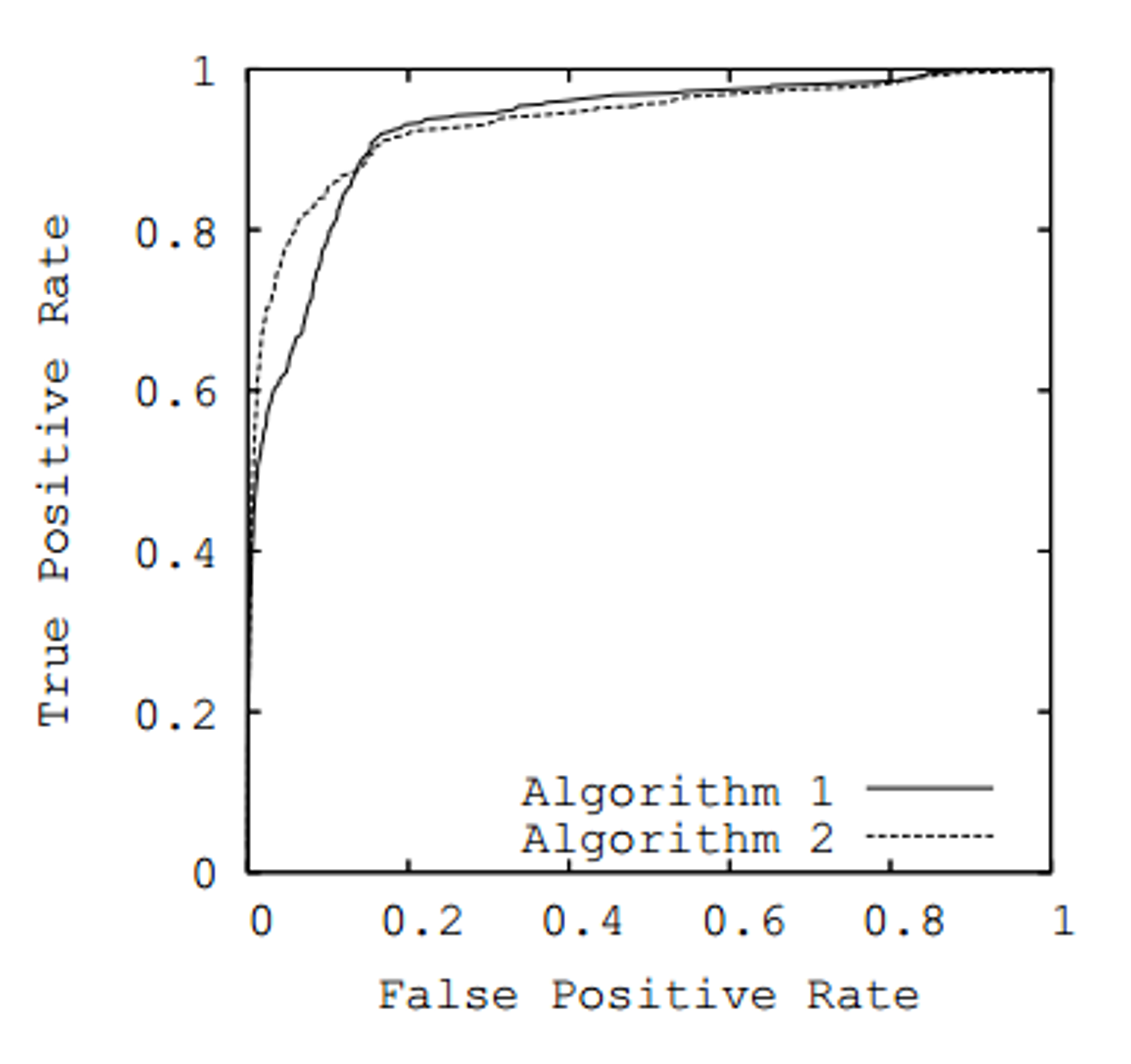

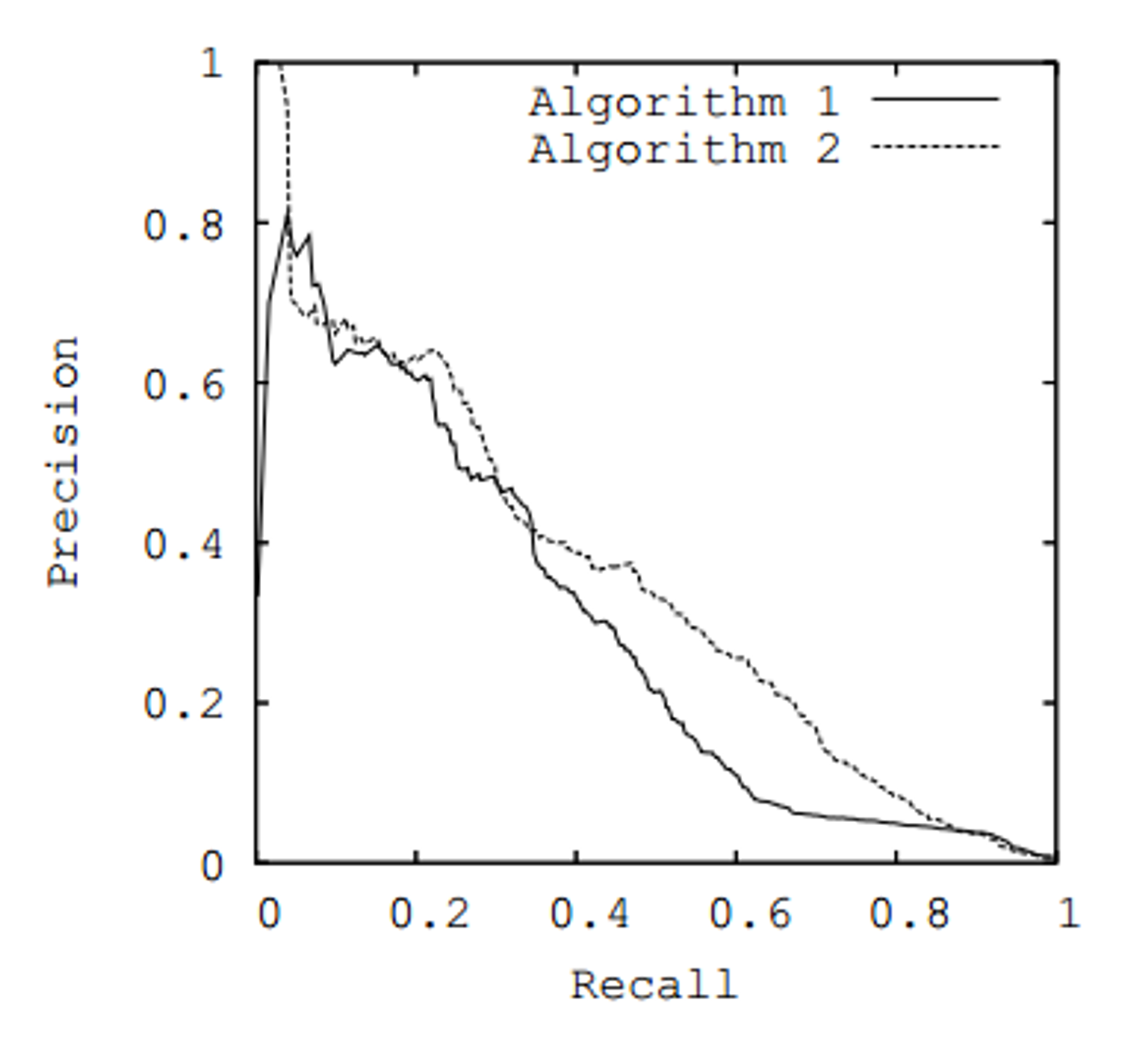
这些曲线是怎么画出来的呢?一般的二分类器是这样子的,我们给它一个输入,分类器会返回一个浮点数字,当这个返回值大于预设定的阈值(比如说,0.5)时,我们认为分类器把输入分为正类;否则,分为负类。这个阈值是我们设定的,如果调小了,就有更多的分到了正类;如果调大了,就有更多的分到了负类。以Precision-Recall 曲线为例,当算法固定不变时,Precision 和 Recall 都是阈值 的函数,所以我们可以通过设置不同的阈值,就可以得到不同的 P-R 对。
一般来说,当模型的 AUC越接近1,这个模型性能越好。因为这意味着随着 Recall 的增大,Precision 仍然保持着在较高的水平。从阈值的角度看,Recall 从小到大,是阈值变小的过程,因为 FN 数量减小了,更多的样本分到了正类。但 Precision 仍保持在较高的水平,FP 数量并没有大幅度增加
对数损失
当一个模型的输出是分类的置信值(Gauge of Confidence)而不是单纯的标签 0 或 1 时,我们可以用对数损失来评估该模型。这样说来比较抽象,请允许我举一个例子。比如我们有一个垃圾邮件分类器,当输入一封垃圾邮件时,它输出正类(1);当输入一封正常邮件时,它输出负类(0)。但现在,它不单单输出 0 或 1 了,对于任意输入,它输出一个数字,代表垃圾邮件的置信值。比如输入一封垃圾邮件,它输出 0.73,代表该输入的垃圾邮件分数为 0.73。这样,由于垃圾邮件分数大于我们预先设置的阈值,比如说0.5,我们会把输入分类到垃圾邮件。
好了,熟悉了模型的置信值输出,我们就可以计算对数损失了。对于二分类问题,对数损失的公式为
其中 是真实的标签,0 或 1; 是模型的输出,像上面提到的 0.73。
回归
回归任务和分类不同,回归是对数值的预测。比如给出往年的苹果产量和必要的一些信息,包括苹果树种植情况,气候等,然后根据今年的苹果树种植情况和气候,预测今年的苹果产量。回归中用到的评估标准有很多,并且和对应的任务息息相关。比如均方根误差(Root Mean Square Error)可以这么来计算
检测
这里说的检测任务是指,在一张图片中,找到目标并框出目标所在的位置,所以也叫目标检测任务(下文会交换使用这两个名字)。也就是说,一般的目标检测算法会输出五个值:目标的类型和检测框的位置(一般是矩形框,用4个值表示)。如果仔细想一想,检测任务和分类是很相近的。早期的检测算法就是用一个窗口在图片上滑动,并把窗口框出来的图片内容一个分类器进行分类,如果分类器分数达到一定阈值,就说算法已经找到了一个目标。这时候检测算法的输出的目标类型就是分类器的输出,目标框位置就是滑动窗口的当前位置。


所以检测任务也常用 Precision 和 Recall 等分类任务指标进行评估。但是想要计算 Precision 和 Recall,我们必须在目标检测任务中定义什么是 TP,FP,FN 和 TN。而在目标检测任务中,这些值的计算都离不开 IoU。
- IoU(Intersection over Union)
- 混淆矩阵(True Positive, False Positive and False Negative)
- Precision 和 Recall
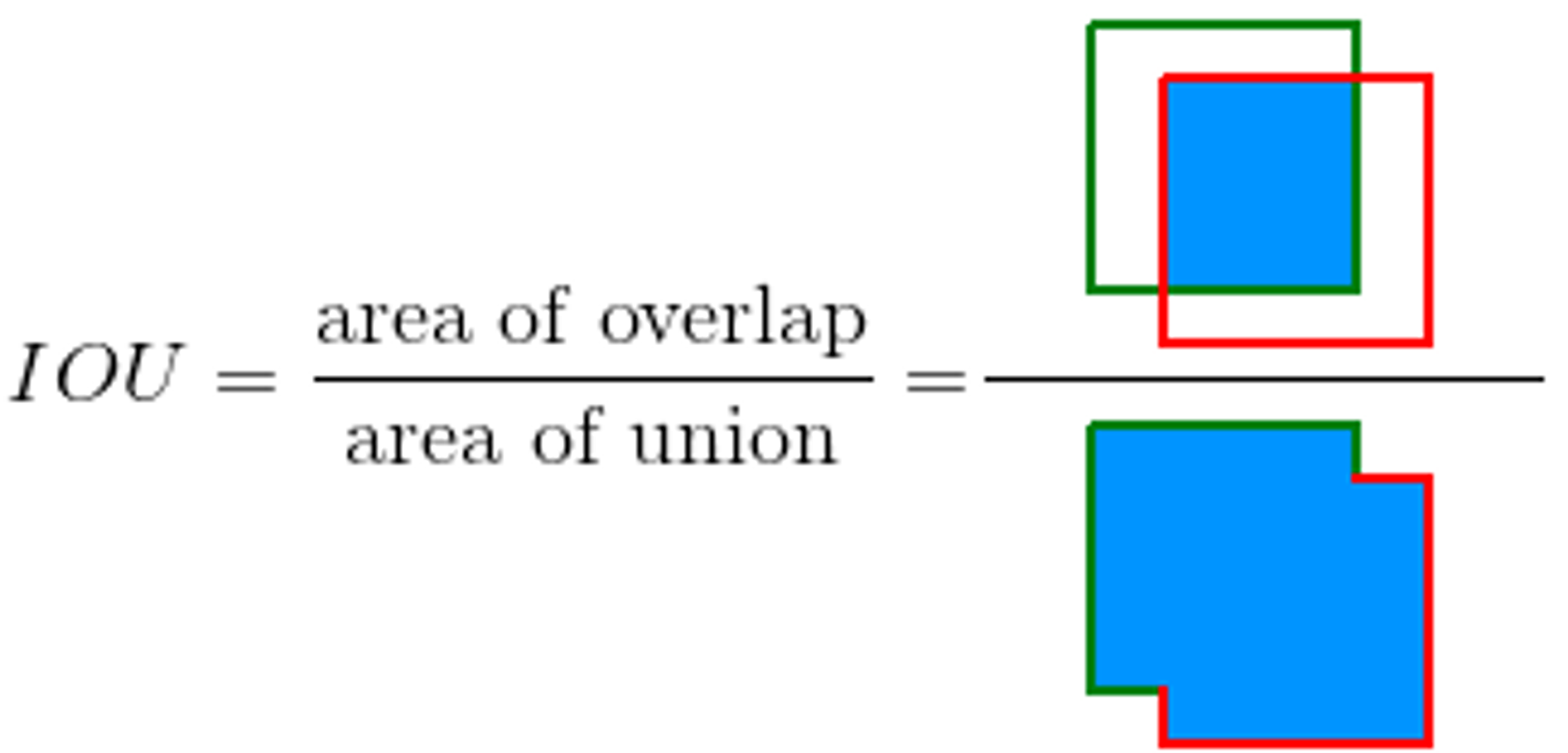
IoU
IoU 字面上的意思是交集和并集的比率,假设我们有两个矩形框,一个是算法输出的检测框 ,一个是真实的目标框 ,那么它们之间的 IoU 为
或者用更形象的方式,可以表示为

混淆矩阵
有了 IoU 的定义,我们就可以计算检测任务的混淆矩阵了。当算法输出的检测框和真实的目标框的 IoU 大于预先设置的阈值时,我们就说预测的矩形框是 True Positive,具体的混淆矩阵定义如下:
- True Positive (TP): A correct detection. Detection with .
- False Positive (FP): A wrong detection. Detection with .
- False Negative (FN): A ground truth goes undetected.
- True Negative (TN): Does not apply
这里面有三点要注意的,1)TN 在检测任务中没有定义,因为 TN 代表的是一个非目标正确地没有被检测出来,而在检测任务中,这样的矩形框的数量是巨大的,且统计这个数字没有太大意义(有兴趣的同学可以计算一下,当图片大小一定比如 时,这个数字应该是一个非常大的但却有限的数字);2)阈值(IoU Threshold)一般是 0.5,0.75 或者 0.95,比如 Pascal VOC 中就是用的 0.5,而 COCO Detection Challange 中都用上了,甚至还用了其他的标准,详情可见其网站;3)当多个检测框和同一个目标框的 IoU 大于阈值时,只有 IoU 最大的那个是 TP,其他的全部是 FP。
Precision 和 Recall
检测任务中的 Precision 和 Recall 和分类任务中的定义是一样的,Precision 表示模型只把目标检测出来的能力,而 Recall 表示模型把全部目标都检测出来的能力,留意它们的计算方式,都没有涉及到 TN,因为 TN 在检测任务中并没有定义。
事实上一般的检测算法除了目标的类型和检测框的位置,还有一个额外的输出,那就是检测框的置信值。所以,我们也可以模仿分类任务,通过使用不同的检测框置信值阈值(注意与 IoU 阈值相区分)得到不同的(Precision,Recall)对,画一条 Precision-Recall 曲线,并用曲线下的面积(AUC)评估检测算法的好坏。